
背景
最近在做接口服务内存和CPU优化,使用Netty版本为netty-all-4.1.29.Final,对于行情数据我们采用Netty的直接内存进行存储,Netty的几种ByteBuf介绍见:Netty常见内存结构 ,当前我们使用的是PooledByteBufAllocator,所以每次内存使用完毕后都需要通过release()方法手动回收直接内存。
使用Netty的直接内存有点与C类似,自己malloc的对象需要自己free;但与C不同的是,在内有引用计数器,外有Java的GC的场景下,Netty直接内存的使用更为复杂,对内存的使用稍有纰漏就会导致整个服务挂掉。在一次优化版本中,就出现了很严重的Netty直接内存泄露的问题。
现象
前一天盘后我们部署了某个优化版本到灰度服务器上,第二天行情数据下发后伴随着用户量增长,接口服务在很短的时间内不可用。
通过运维平台调取了当天该服务器上的内存使用情况:
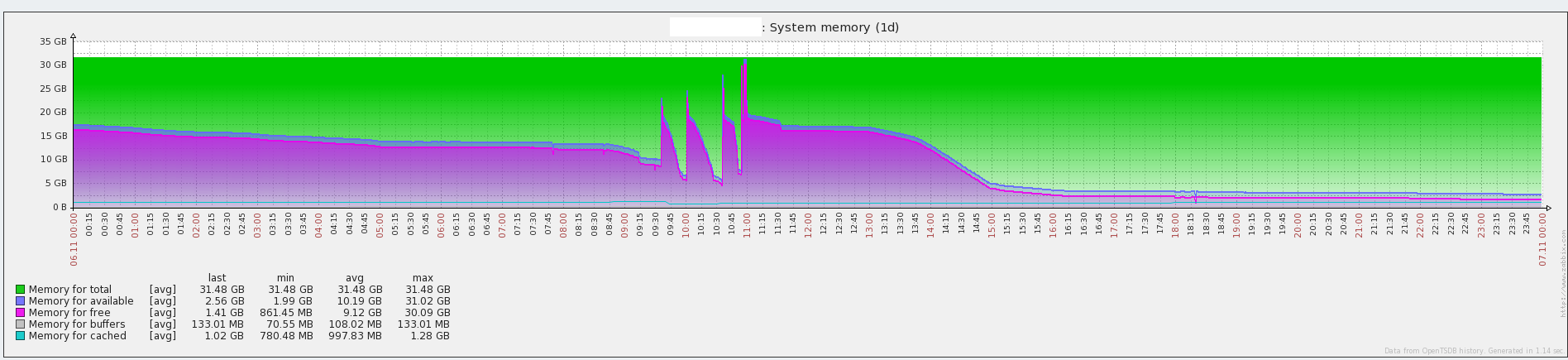
可以发现在上午9:00~11:00时间段内,接口服务多次挂掉后自动重启,中午版本回退后服务才恢复正常。
排查过程
一、查看系统日志
首先查看服务异常时间段内服务器上的日志,可以发现在短时间内日志打印了非常多的直接内存分配异常OutOfDirectMemoryError:

日志显示直接内存Direct Memory不够用了,该服务器上配置了堆内存12G,直接内存18G,与异常中打印的最大可分配直接内存相匹配;

根据之前的内存使用情况可以断定在服务正常状态下,18G直接内存是能满足接口服务使用场景的,那就可以断定单纯地在配置中增大可分配直接内存的大小不能解决问题。
二、确认异常抛出原因
通过上面OOM异常日志,可以追踪到PlatformDependent.java的incrementMemoryCounter(int capacity)方法。
我们可以看到这个方法是Netty自身对已使用直接内存进行计数,当计数器DIRECT_MEMORY_COUNTER已使用内存大于直接内存上限DIRECT_MEMORY_LIMIT时,抛出一个OutOfDirectMemoryError异常,这个直接内存上限即上面我们在配置文件中通过-XX:MaxDirectMemorySize配置的。关于Netty的OutOfDirectMemoryError问题见:关于Netty的OutOfDirectMemoryError问题 。
无法分配直接内存无非是以下两种情况导致的:
- 分配的直接内存最终没有
release()掉,使直接内存不断被分配使用而没有回收掉,最终达到可用上限产生内存泄露; - 因用户网络异常或者传输的数据量过大等问题,使得直接内存的释放回收速度小于其分配的速度,最终无内存可分配抛出OOM。
如果是前者,就需要找出没有正确release()的代码进行修改;如果是后者,则需要在write的时候,添加流控措施,避免到达内存限制。
三、Netty内存泄漏的监测机制
Netty本身提供了内存泄漏的监测机制(详细介绍见:Netty引用计数对象),我们可以通过在配置文件中配置-Dio.netty.leakDetectionLevel对分配的ByteBuf进行跟踪。

如果服务有内存泄露,则会打印如下日志:
LEAK: ByteBuf.release() was not called before it’s garbage-collected. Enable advanced leak reporting to find out where the leak occurred. To enable advanced leak reporting, specify the JVM option ‘-Dio.netty.leakDetectionLevel=paranoid’ or call ResourceLeakDetector .setLevel()
因为是功能测试,所以在异常服务上,我将监测的级别配置为paranoid,运行一段时间后查看服务日志,发现并未有LEAK 日志打印,看来通过Netty自身的监测机制定位问题这条路走不通。
四、Arthas查看直接内存使用情况
我们知道服务是因为已使用直接内存达到了可分配上限才挂掉的,那通过查看服务器上DIRECT_MEMORY_COUNTER的大小能不能发现问题呢?这时候不得不提到Java诊断神器Arthas了(详细介绍见:介绍一款开源Java诊断工具—Arthas )。
通过Arthas进入到当前服务进程,执行sc命令来查看PlatformDependent.java类的成员变量:
sc -df io.netty.util.internal.PlatformDependent
可以看到命令执行后当前时间的已分配直接内存和可分配直接内存上限两个参数的值:
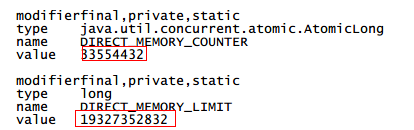
使用Arthas来查看确实简单便捷,但是因为只能查看一个时间点的变量的值(也可能是我的打开方式不对),对我们解决问题帮助不是很大,所以还是用笨办法吧,即通过起一个线程来定时打印直接内存的值。
五、日志打印直接内存
直接内存定时打印
这里我写了一个线程,每两秒将通过反射获取的DIRECT_MEMORY_COUNTER参数的值在日志中实时打印出来,方便我们调试。
模拟客户端进行压力测试
为了能明显地看到内存分配的数值变化,这里我通过编写TestMain模拟客户端用户来请求接口服务数据;
并设置模拟用户量为200,将有问题的服务部署到开发服务器上进行压力测试。

日志分析
首先将开发服务器上接口服务启动,这是当前服务的端口连接数为0,即没有用户访问,这时服务已使用的直接内存维持在一个稳定的值256MB(如下图前几条日志所示);当把压力测试程序启动,随着用户连接数涨到200,服务已使用的直接内存迅速飙升(如下图选中日志所示),一直达到可用内存上限18G,最终导致服务不可用,整个用时不到5分钟!

到这里我们可以得出结论,本次内存泄露与接口服务处理上游数据的过程无关,而是在处理用户请求并返回数据的过程中抛出的。
到这里问题的定位范围进一步缩小,我还是采用了虽然繁琐但是直接有效的方法:范围从大到小地对请求返回数据过程中分配及使用直接内存的代码块进行注释,并部署到开发服务器上进行测试。
其中的具体操作过程略去不表,其实结果证明这个方法确实是很有效的,我只重新部署哦了两次服务就找到了问题代码:
当我把上图选中代码注释掉后,再进行压力测试接口服务已使用直接内存的值维持在256MB不再增长,如下图所示:
进入到callback()方法最终修改了下图所示代码,对已分配但未使用的直接内存进行release()回收释放,重新部署,测试通过。
六、后续
我提交了代码盘后通过CI重新发布到之前出现异常的服务器上,几个交易日过去了,问题没有再出现。
结论
1.对于Netty直接内存问题,我们可以通过三种手段来定位问题:Netty自身的内存泄露监测机制;Arthas等第三方工具;反射获取并打印直接内存数值。
2.这次问题的出现是只在ByteBuf使用之后进行了回收,没有考虑到在异常情况下ByteBuf没有成功传递到下一个Hanlder(其实考虑到了,只不过疏忽了这个分支),这时也要把分配了没有使用的直接内存进行回收。
3.至于为什么Netty自身的监测机制没有打印LEAK日志,后面我会再研究一下。
最后希望大家都能:
