
文章概要
最近看了阿里中间件团队的几篇技术博客,详情见:阿里中间件团队博客,其中有关RocketMQ的几篇文章写得很好。还是那句话,学习本身就是一个不断获取知识然后投入实践的过程,本文就组内项目中使用的RocketMQ集成Spring Boot框架来实现消息发送消费的解决方案进行一个简单的梳理。鉴于自身当前对中间件优化方面还没有太深的接触,文中有可能会出现一些理解错误,难免不贻笑大方,所以权当成个人的学习笔记,方便记忆和以后的深入学习。
设计实现
前言
为什么选择 Spring Boot集成RocketMQ作为行情组合计算服务的消息队列解决方案?迫于排版限制,其原因我放在了文章最后的补充目录下,下面是跳转链接:
同时你也可以获取一些RocketMQ的简单介绍:
下面我将开门见山地对其实现细节进行介绍:
配置文件
- 配置pom.xml文件
1 | <dependency> |
1 | <dependency> |
- spring-boot应用中对应的配置文件:src/main/resources/application.properties.
生产端的配置文件application.properties
1 | # 定义name-server地址 |
消费端的配置文件application.properties
1 | # 定义name-server地址 |
消息生产端的设计实现
生产端的Java代码如下:
消息生产者类:
1 | public class MQPushProducer<T> { |
RocketMQ通过轮询所有队列的方式来确定消息被发送到哪一个队列(负载均衡策略)。可以根据业务实现自己的MessageQueueSelector()发送顺序消息。
MQPushProducerOrderly类:
1 | public class MQPushProducerOrderly<T> extends MQPushProducer { |
消息生产端启动类:
1 |
|
关于@SpringBootApplication注解相关参见:@SpringBootApplication 注解简析
在整个应用生命周期内,生产者需要调用一次start方法来初始化,初始化主要完成的任务有:
- 如果没有指定namesrv地址,将会自动寻址;
- 启动定时任务:更新namesrv地址、从namsrv更新topic路由信息、清理已经挂掉的broker、向所有broker发送心跳等;
- 启动负载均衡的服务。
如果Producer发送消息失败,会自动重试,重试的策略:
重试次数 < retryTimesWhenSendFailed(可配置);
总的耗时(包含重试n次的耗时) < sendMsgTimeout(发送消息时传入的参数);
同时满足上面两个条件后,Producer会选择另外一个队列发送消息。
消息消费端设计实现
消息消费端代码如下:
消息消费者类:
1 | public abstract class MQPushConsumer { |
MQPushConsumerOrderly类:
1 | public abstract class MQPushConsumerOrderly extends MQPushConsumer{ |
注册监听类的时候,不能使用匿名内部类。不然的话只消费一次消费者就挂了, 监听类要单独写。
自定义监听类:
1 | public class MQMessageListenerOrderly implements MessageListenerOrderly { |
消息消费端启动类:
1 |
|
以上就是一个简单的使用Spring Boot框架集成RocketMQ实现基本的消息发送和接收的实例,在以后的工作中对RocketMQ的事务消费、消息存储有深入的理解再另行整理。
补充
关于Spring Boot
Spring Boot 是由 Pivotal 团队提供的全新框架,其设计目的是用来简化新 Spring 应用的初始搭建以及开发过程。该框架使用了特定的方式来进行配置,从而使开发人员不再需要定义样板化的配置。通过这种方式,Spring Boot 致力于在蓬勃发展的快速应用开发领域(rapid application development)成为领导者。
Spring Boot基于“约定大于配置”(Convention over configuration)这一理念来快速地开发、测试、运行和部署Spring应用,并能通过简单地与各种启动器(如 spring-boot-web-starter)结合,让应用直接以命令行的方式运行,不需再部署到独立容器中。这种简便直接快速构建和开发应用的过程,可以使用约定的配置并且简化部署,受到越来越多的开发者的欢迎。
Kafka、RocketMQ、RabbitMQ的比较
Kafka是LinkedIn开源的分布式发布-订阅消息系统,目前归属于Apache顶级项目。Kafka主要特点是基于Pull的模式来处理消息消费,追求高吞吐量,一开始的目的就是用于日志收集和传输。0.8版本开始支持复制,不支持事务,对消息的重复、丢失、错误没有严格要求,适合产生大量数据的互联网服务的数据收集业务。
大型公司建议可以选用,如果有日志采集功能,肯定是首选kafka了。
RabbitMQ是使用Erlang语言开发的开源消息队列系统,基于AMQP协议来实现。AMQP的主要特征是面向消息、队列、路由(包括点对点和发布/订阅)、可靠性、安全。AMQP协议更多用在企业系统内,对数据一致性、稳定性和可靠性要求很高的场景,对性能和吞吐量的要求还在其次。
结合erlang语言本身的并发优势,性能较好,社区活跃度也比较高,但是不利于做二次开发和维护。不过,RabbitMQ的社区十分活跃,可以解决开发过程中遇到的bug。
如果你的数据量没有那么大,小公司优先选择功能比较完备的RabbitMQ。
RocketMQ是阿里开源的消息中间件,它是纯Java开发,具有高吞吐量、高可用性、适合大规模分布式系统应用的特点。RocketMQ思路起源于Kafka,但并不是Kafka的一个Copy,它对消息的可靠传输及事务性做了优化,目前在阿里集团被广泛应用于交易、充值、流计算、消息推送、日志流式处理、binglog分发等场景。
天生为金融互联网领域而生,对于可靠性要求很高的场景,尤其是电商里面的订单扣款,以及业务削峰,在大量交易涌入时,后端可能无法及时处理的情况。
RoketMQ在稳定性上可能更值得信赖,这些业务场景在阿里双11已经经历了多次考验,如果你的业务有上述并发场景,建议可以选择RocketMQ。
关于RocketMQ的一些概念
Producer:消息生产者,生产者的作用就是将消息发送到 MQ,生产者本身既可以产生消息,如读取文本信息等。也可以对外提供接口,由外部应用来调用接口,再由生产者将收到的消息发送到 MQ。
Producer Group:生产者组,简单来说就是多个发送同一类消息的生产者称之为一个生产者组。在这里可以不用关心,只要知道有这么一个概念即可。
Consumer:消息消费者,简单来说,消费 MQ 上的消息的应用程序就是消费者,至于消息是否进行逻辑处理,还是直接存储到数据库等取决于业务需要。
Consumer Group:消费者组,和生产者类似,消费同一类消息的多个 consumer 实例组成一个消费者组。
Topic:Topic 是一种消息的逻辑分类,比如说你有订单类的消息,也有库存类的消息,那么就需要进行分类,一个是订单 Topic 存放订单相关的消息,一个是库存 Topic 存储库存相关的消息。
Message:Message 是消息的载体。一个 Message 必须指定 topic,相当于寄信的地址。Message 还有一个可选的 tag 设置,以便消费端可以基于 tag 进行过滤消息。也可以添加额外的键值对,例如你需要一个业务 key 来查找 broker 上的消息,方便在开发过程中诊断问题。
Tag:标签可以被认为是对 Topic 进一步细化。一般在相同业务模块中通过引入标签来标记不同用途的消息。
Broker:Broker 是 RocketMQ 系统的主要角色,其实就是前面一直说的 MQ。Broker 接收来自生产者的消息,储存以及为消费者拉取消息的请求做好准备。
Name Server:Name Server 为 producer 和 consumer 提供路由信息。
RocketMQ的概念模型如下:
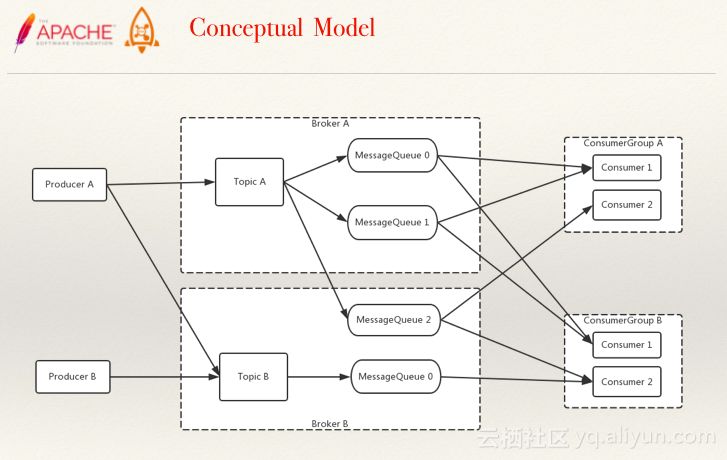
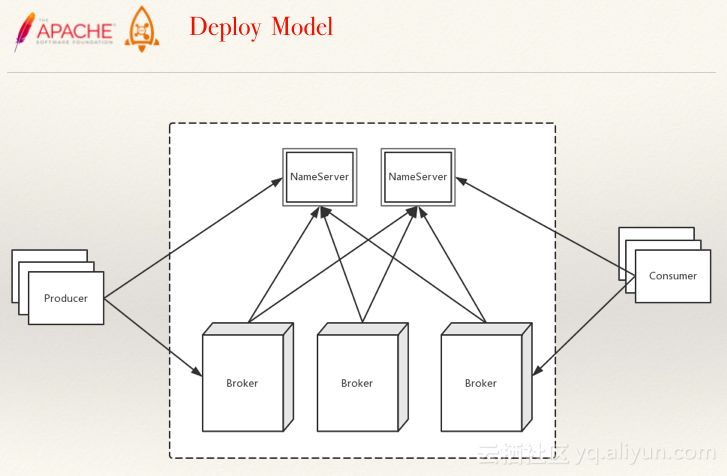
RocketMQ的部署模型如下:
@SpringBootApplication 注解简析
@SpringBootApplication = @SpringBootConfiguration + @EnableAutoConfiguration + @ComponentScan。
因为@SpringBootConfiguration ,@EnableAutoConfiguration,@ComponentScan这些注解一般都是一起使用来注解mian()方法所在的类,所以Spring Boot提供了一个统一的注解@SpringBootApplication。
@SpringBootConfiguration继承自@Configuration,二者功能也一致,标注当前类是配置类,并会将当前类内声明的一个或多个以@Bean注解标记的方法的实例纳入到Spring容器中,并且实例名就是方法名。- @EnableAutoConfiguration的作用启动自动的配置,@EnableAutoConfiguration注解的意思就是Springboot根据你添加的jar包来配置你项目的默认配置,比如根据spring-boot-starter-web,来判断你的项目是否需要添加了webmvc和tomcat,就会自动的帮你配置web项目中所需要的默认配置。在下面博客会具体分析这个注解,快速入门的demo实际没有用到该注解。
- @ComponentScan,扫描当前包及其子包下被@Component,@Controller,@Service,@Repository注解标记的类并纳入到spring容器中进行管理。是以前的
<context:component-scan>(以前使用在xml中使用的标签,用来扫描包配置的平行支持)。所以本demo中的User为何会被spring容器管理。