简介
中文译名:Dynamo:Amazon的高可用性的键-值存储系统
论文于 2007 年首次发表,并在 Werner Vogels 的博客上得到推广,至今有着 4k+ 的引用量,是分布式存储系统中的一篇经典论文。
本文尝试对其进行简单翻译,受翻译水平所限,难免有翻译或理解错误,如有疑问烦请查阅原文:原文地址。
以下是译文。
[TOC]
摘要
超大规模下的可靠性问题是我们在 Amazon.com——世界上最大的电商之一——所要面对的最大挑战之一;即使是最轻微的故障也会造成严重的经济后果,并影响客户对我们的信任。Amazon.com 作为一个为全球提供 web 服务的平台,其底层的基础设施是由遍布全球的数据中心中成千上万的服务器和网络设备所组成的。在这种规模下,各种大大小小的部件故障持续发生,而我们面对这些故障时所采取的管理持久化状态的方式,驱动着软件系统的可靠性和可扩展的发展。
本文介绍了 Dynamo——一个高可用的 KV 存储系统——的设计和实现,Amazon 的一些核心服务就是借助 Dynamo 来提供“永远在线”的用户体验(“always-on” experience)的。为了达到这种级别的可用性,Dynamo 牺牲了在某些故障的场景下的一致性。它广泛地使用了对象版本控制(object versioning)和应用辅助的冲突解决(application-assisted conflict resolution)机制,为开发人员提供了一个可以使用的新接口。
1. 引言
Amazon 是一个全球性的电商平台, 高峰期用户可达数千万,背后是靠分布在全球的若干数据中心中的成千上万的服务器来支撑。平台对性能、可靠性和效率方面有着严格的要求,并且为了支持持续增长,高度的可扩展性也是不可或缺的。其中可靠性是最重要的要求之一,因为即使是最轻微的故障也会造成严重的经济后果,并影响客户对我们的信任。
我们从运营 Amazon 平台的过程中总结出的经验之一是,一个系统的可靠性和可扩展性取决于它的应用状态是如何管理的。Amazon 使用的是一种由数百个服务器组成的高度去中心化、松耦合、面向服务的架构。这样的环境特别需要永远可用(always available)的存储技术。例如,即使磁盘故障,路由抖动,甚至是数据中心被龙卷风摧毁,用户应依然可以查看和添加商品到自己的购物车。因此,负责管理购物车的服务就必须始终能够对其数据存储进行读写,并且其数据需要跨多个数据中心可用。
在一个由数百万个组件组成的基础设施中,进行故障处理是我们习以为常的操作模式;任何时间都会有少部分但也有相当数量的服务器和网络组件发生故障。因此,Amazon 的软件系统需要以一种将故障处理视为正常情况的方式构建,不能因设备故障影响可用性或性能。
为了满足可靠性和可扩展性的需求,Amazon 开发了许多存储技术,其中 Amazon Simple storage Service(也可以从 Amazon 外部获得,称为 Amazon S3)可能是最为人熟知的。本文介绍了Dynamo 的设计与实现,这是另一个为 Amazon 平台构建的高可用性和可扩展的分布式数据存储。Dynamo 被用于管理对可靠性要求非常高的服务的状态,同时这些服务还要求能够严格控制可用性、一致性、成本效益和性能之间的权衡。Amazon 平台拥有非常多样化的应用,不同应用有着不同的存储需求。一部分应用需要存储技术具有足够的灵活性,以便在最具成本效益的方式下,让应用程序设计人员能够合理地配置数据存储,最终实现高可用性和性能保证之间的平衡。
Amazon服务平台中的许多服务只需要主键访问数据存储。对于许多服务,如提供畅销排行榜、购物车、客户的偏好、会话管理、session 管理、销售排名、商品目录等等,常见的使用关系数据库的模式会导致效率低下,而且限制了规模的扩展性和可用性。Dynamo 提供了一个简单的主键唯一(primary-key only)访问接口以满足这些应用的要求。
Dynamo 综合使用了一些众所周知的技术来实现可伸缩性和可用性:使用一致性哈希(consistent hashing)[10]对数据进行分散和复制,并且通过对象版本控制(object versioning)[12]促进了一致性。在更新期间,副本之间的一致性由类仲裁(quorum-like)技术和去中心化的副本同步协议(replica synchronization protocol)来维护。Dynamo 采用基于gossip的分布式故障检测和成员协议。Dynamo 是一个只需最少人工管理的、完全去中心化的系统。从 Dynamo 中添加和删除存储节点不需要任何手动分区(partition)或重新分配(redistribution)。
在过去的一年,Dynamo 已经成为 Amazon 电商平台很多核心服务的底层存储技术。在节假日购物高峰,它能够有效地扩容以支持极高的峰值负载,而不需要任何停机时间。例如,维护购物车的服务(Shopping Cart Service)能处理数千万个请求,这些请求会产生单日超过 300 万次的付款动作;管理会话状态的服务能处理数十万的并发活跃会话等。
这项工作对研究社区的主要贡献是评估了如何通过组合不同技术以实现一个高可用的系统。它论证了一个最终一致性(eventually-consistent)的存储系统可以被用于生产环境中有着苛刻要求的应用。它也对这些技术的调整进行了深入的分析,以满足生产环境的非常严格的性能要求。
本文的结构如下。Section 2 为背景,Section 3 为相关工作,Section 4 介绍了系统设计,Section 5 描述了实现,Section 6 详细介绍了在生产中运行 Dynamo 的经验和体会,Section 7 总结全文。在本文的许多地方也许可以适当有更多的信息,但出于适当保护 Amazon 的商业利益,需要减少一些细节。因此,第6节中的数据中心内部和跨数据中心之间的延迟(the intra- and inter-datacenter latencies)、第6.2节中的绝对请求速率(absolute request rates)以及第6.3节中的系统中断时间和工作负载(outage lengths and workloads),都只是概述而没有提供具体细节。
2. 背景
Amazon 的电商平台由数百个服务组成,它们协同工作,提供了从推荐系统到订单处理,再到欺诈检测等一系列的功能。每个服务都对外提供明确的接口,并且能够通过网络访问。这些服务运行在遍布全球的数据中心中的数万台服务器组成的基础设施之上。其中有些服务是无状态的(例如,聚合其他服务的响应的服务),有些是有状态的(例如,在其存储在持久存储中的状态上,执行业务逻辑并生成响应的服务)。
传统的生产系统使用关系型数据库来存储状态。然而,对于许多更常见的状态持久性使用模式来说,关系型数据库远非理想的解决方案。因为这些服务大多只通过主键存储和检索数据,并不需要RDBMS 提供的复杂查询和管理功能。而这些多余的功能的运作需要昂贵的硬件和高技能人员,这就使其成为一个非常低效的解决方案。此外,现有的复制技术是有限的,而且通常是靠牺牲可用性来换一致性。尽管近年来已经取得了许多进展,但是要水平扩展(scale-out)或使用智能分区方案(smart partitioning schemes)来实现负载平衡仍然不是一件容易的事情。
本文介绍了 Dynamo,这个高可用的数据存储技术能够满足这些重要类型的服务的需求。Dynamo 有易用的 key/value 接口,是高可用的并有定义清晰的一致性窗口(clearly defined consistency window),资源利用率高,并且有易用的解决请求量或数据规模增长的水平扩展方案。每个使用Dynamo的服务都独立运行自己的Dynamo实例。
2.1 系统假设与要求
这类服务的存储系统有以下要求:
查询模型(Query Model):通过一个主键唯一性标识对数据项进行简单的读写操作。状态存储为以唯一键索引的二进制对象(例如,blobs)。没有跨多个数据项的操作,也不需要关系模式(relational schema)。这一要求是考虑到,相当一部分 Amazon 的服务可以使用这个简单的查询模型,并不需要任何关系模式。Dynamo 的目标应用需要存储的对象都比较小(通常小于1MB)。
ACID属性:ACID(Atomicity, Consistency, Isolation, Durability)是一组保证数据库事务可靠执行的属性。在数据库领域,对数据的单次逻辑操作称为事务。Amazon 的经验表明,保证ACID的数据存储往往可用性很差,这一点已被业界和学术界广泛认可 [5]。Dynamo 的目标应用能容忍较弱的一致性(ACID中的“C”),前提是可用性能够得到提升。Dynamo 不提供任何隔离保证,并且只允许单个 key 的更新。
效率(Efficiency):系统需要在普通硬件基础设施(commodity hardware infrastructure)上运行。Amazon 平台的服务对延迟有着严格的要求,描述服务的响应时间要求时以99.9百分位点(译者注,缩写为p999)为准。鉴于状态数据访问是服务的核心操作之一,存储系统必须满足那些严格的SLA (见 Section 2.2)。服务要有配置 Dynamo 的能力,使其最终能达到延时和吞吐量的要求。因此,就需要在性能、成本效率、可用性和持久性保证之间做权衡。
其他假设:Dynamo 仅限在 Amazon 内部的服务上使用。因此我们假定它的操作环境是安全的,不需要考虑身份验证和授权等安全相关的需求。此外,由于每个服务都使用其不同的Dynamo实例,所以它的初始设计目标是扩展到数百台存储主机。我们将在后面的章节讨论 Dynamo 的可扩展性限制的问题,以及可能的解决方案。
2.2 服务质量协议 (Service Level Agreements,SLA)
为了确保应用程序能够在有限时间内做出响应,平台中的每个依赖项的响应就需要有更严格的时限。客户端和服务端采用服务质量协议(SLA),该协议即为客户端和服务端在某些系统层面的指标上达成一致的一个正式协商合约。这些指标主要包括客户端对特定 API 的请求速率分布的期望值,以及在这些条件下的预期服务延迟。一个简单的 SLA 例子:服务端保证在 500 QPS 的峰值负载下,99.9% 的请求响应时间在 300ms 以内。
在 Amazon 的去中心化的、面向服务的基础设施中,SLA 扮演着重要角色。例如,对某个电商网站发送一个页面请求,通常需要渲染引擎通过发送请求到150多个服务来构建其响应。这些服务一般有多个依赖,而这些依赖又往往是其他服务,因而一个应用有着多层调用路径的情况并不少见。为了确保网页渲染引擎能在明确的时间限制内返回结果页面,调用链内的每个服务就都必须遵循合约中的性能指标。
图1展示了 Amazon 平台抽象的架构图,动态 web 内容由页面渲染组件(page rendering components)生成,而组件向下又会去调用一些其他的服务。一个服务可以使用不同的数据存储来管理它的状态数据,这些数据存储只能在各自的服务范围才能访问。一些服务充当聚合器的角色,通过聚合其他服务的数据来返回一个组合响应。通常情况下,聚合器服务是无状态的,尽管它们使用广泛的缓存(extensive caching)。
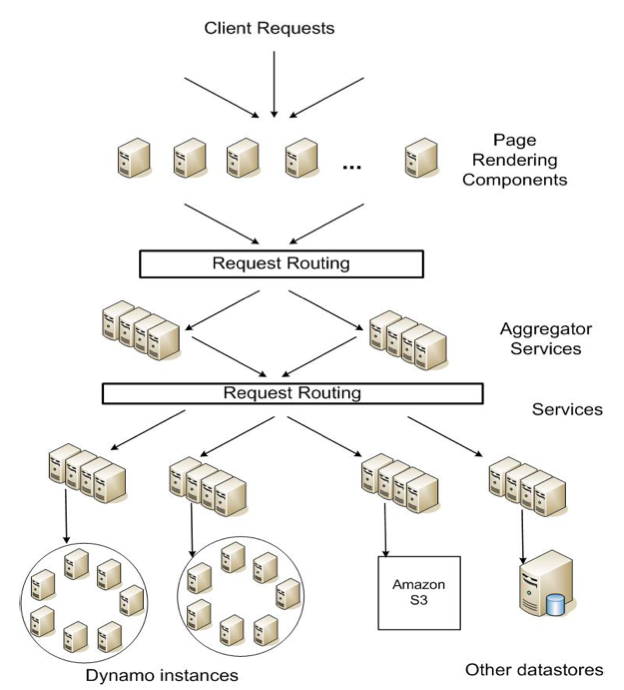
图 1:Amazon 平台的面向服务架构
行业内通常习惯于用平均数(average)、中位数(median)和期望方差(expected variance)来描述面向性能的 SLA。但是,在 Amazon 我们发现,如果我们的目标是打造一个让所有用户都有良好体验的系统,而不仅仅是大部分用户的话,以上这些指标是不够好的。例如,如果个性化推荐技术(personalization techniques)被广泛地使用,那么用户的访问历史越多,对该用户就需要做更多的处理,这将影响到数值分布高端区(high-end of the distribution)的性能(译者注,即响应时间的高百分位点,也称为尾部延迟(tail latencies))。基于平均数或中位数响应时间的 SLA 不能反映这一最有价值客户段的性能需求。为了解决这个问题,在 Amazon,SLA是基于分布的99.9百分位点来表达和测量的。选择99.9%而不是更高,是因为根据成本效益(cost-benefit)分析发现,再继续提高性能,所需的成本将大幅提高。在 Amazon 的生产环境中证实,相比于那些基于平均数或中位数定义的 SLA 的系统,该方法提供了更好的用户体验。
本文多次提到p999,这也反映了 Amazon 工程师从客户体验角度对性能的不懈追求。许多论文都是关于平均数的,所以我们在用作比较时也会引用。不过,Amazon的工程和优化都不是以平均数为关注点。某些技术,例如写协调器(write coordinators)的负载均衡选择,纯粹是基于p999来控制性能的。
存储系统在建立一个服务的SLA中通常扮演重要角色,特别是在业务逻辑相对轻量的场景下,正如许多 Amazon 服务的情况。因而状态管理就成为一个服务的 SLA 的主要组成部分。Dynamo 的主要设计考虑之一就是允许服务控制它们自己的系统属性,例如持久性和一致性,并让服务自己在功能,性能和成本效益之间进行权衡。
2.3 设计考虑
传统上,商业系统中使用的数据复制(data replication)算法执行同步复制协调(synchronous replica coordination ),以提供一个强一致性的数据访问接口。为了达到这种程度的一致性,这些算法被迫牺牲了某些故障情况下的数据可用性。例如,当数据冲突时不去确定返回数据是否正确,而是直接使数据不可用,直到数据最终一致。从非常早期的复制数据库(replicated database)工作可以看出,当网络故障时,强一致性、数据高可用性是无法同时满足的 [2, 11]。因此,系统和应用程序需要知道,在什么场景下应该选择满足什么特性。
对于容易出现服务器和网络故障的系统,可以通过使用乐观复制(optimistic replication )技术来提高可用性,在后台将数据变动同步到其他节点,同时并发、断线(disconnected)也是可以容忍的。这种方法的问题在于它会导致更改冲突,需要检测并解决冲突。解决冲突的过程引入了两个问题:何时解决,谁来解决?Dynamo 被设计成最终一致(eventually consistent)的数据存储,即所有的更新最终会达到所有副本。
一个重要的设计考虑是决定何时去解决更新冲突,例如,是在读的时候解决冲突,还是在写的时候。许多传统数据存储在写的过程中解决冲突,从而保证读的复杂度相对简单 [7]。在这种系统中,如果在给定的时间内数据存储不能访问所有(或大部分)副本,写就会被拒绝。另一方面,Dynamo 的目标是设计一个“永远可写”(always writable)的数据存储(例如,一个对写操作高度可用的数据存储)。对于 Amazon 的许多服务来讲,拒绝用户的更新操作可能会导致糟糕的用户体验。比如,即使发生服务器或网络故障,购物车服务也必须允许用户仍然可以向购物车中添加或删除商品。这一要求迫使我们将解决冲突的复杂性推给读操作,以确保写操作永远不会被拒绝。
下一个需要考虑的问题是由谁来解决冲突。这可以通过数据存储或应用程序来完成。如果由数据仓库来执行,那么选择就相当有限。在这种情况下,数据仓库只能使用一些简单的策略,如“最后一次写有效”(last write wins) [22],来解决更新冲突。而另一方面,因为应用程序清楚数据结构(data schema),所以它可以决定最适合用户体验的冲突解决方法。例如,维护用户购物车的应用可以选择“合并”冲突的版本,并返回一个统一的购物车。尽管这样很灵活,但一些应用开发人员并不想自己实现一套冲突解决机制,他们选择将问题下放给数据存储,最终数据存储选择诸如“最后一次写有效”这种简单的策略去解决。
设计中需要考虑的其他设计原则:
增量扩展性(Incremental scalability):Dynamo 应支持一次水平扩展一台存储主机(以下,简称为“节点“),而且对系统操作者和系统本身的影响很小。
对称性(Symmetry):Dynamo 每个节点的职责应该是相同的;不应当出现某个/某些节点承担特殊角色或额外职责的情况。根据我们的经验,对称性简化了系统的配置和维护。
去中心化(Decentralization):是对称性的扩展,系统设计应采用去中心化的、点对点的技术,而不是集中控制。在过去,集中控制的设计导致发生了很多系统中断(outages),我们的目标就是尽可能避免它。去中心化会使得系统更简单、更具扩展性和可用性。
异构性(Heterogeneity):系统需要能够在其运行的基础设施中利用异构性。例如,负载的分布必须与各个服务器的能力成比例。样就可以一次只增加一个能力更强的新节点,而无需一次升级所有节点。
3. 相关工作
3.1 点对点系统(Peer to Peer Systems)
已经有几个点对点(peer-to-peer, P2P)系统研究过数据存储和分发的问题。第一代 P2P 系统,例如 Freenet 和 Gnutella,被主要用作文件共享系统。这些都是非结构化 P2P 网络( unstructured P2P networks)的例子,节点之间的 overlay 链路都是随意建立的。在这些网络中,一次查询请求通常泛洪到整个网络,以找到尽可能多的共享该数据的节点。P2P 系统演进到下一代,就是广为人知的结构化 P2P 网络(structured P2P networks)。这种网络采用了全局一致的协议,以确保任何节点都可以高效地将查询请求路由到那些具有所需数据的节点。诸如 Pastry [16] 和 Chord [20] 的系统使用路由机制,保证查询能在有限数量的跳(a bounded number of hops)内得到应答。
为了减少多跳(multi-hop)路由带来的额外延迟,一些 P2P 系统(例如 [14])采用了
O(1) 路由机制,即每个节点在本地维护足够多的路由信息,以便可以在固定数量的跳(a constant number of hops)内将(访问数据的)请求路由到合适的节点。
很多存储系统, 例如Oceanstore [9] 和 PAST [17],都是构建在这种路由 overlay 之上的。Oceanstore 提供了一个全局的、事务性的、持久的存储服务,支持对广泛分布的数据副本进行串行化更新。为了在避免广域锁(wide-are locking)固有的许多问题的同时支持并发更新,它使用了一 种基于冲突解决的更新模型。在[21]中介绍了冲突解决,被用于减少事务异常中止的数量。Oceanstore 通过处理一系列的更新,对更新整体排序,并按照顺序进行原子更新的方式解决冲突。它是为在未受信任的基础设施上进行数据复制的场景设计的。相比之下,PAST 在 Pastry 之上为持久的和不可变的对象提供了一个简单的抽象层。它假定应用程序可以在它之上建立必要的存储语义(如可变文件)。
3.2 分布式文件系统与数据库
文件系统和数据库系统社区已经对分布式数据的性能、可用性和持久性进行了广泛研究。与 P2P 存储系统只支持扁平命名空间(flat namespace)相比,分布式文件系统通常都支持层级化(hierarchical )的命名空间。诸如 Ficus [15] 和 Coda [19] 的系统通过文件复制以牺牲一致性为代价来实现高可用。而更新冲突通常使用专门的冲突解决策略来处理。Farsite 系统 [1] 是一个不使用任何中央服务器(比如 NFS)的分布式文件系统。Farsite 使用复制来实现高度的可用性和可扩展性。谷歌文件系统(Google File System,GFS) [6] 是另一个分布式文件系统,它被用于承载 Google 内部应用的状态数据。GFS 的设计很简单,通过一个主节点(master)管理整个元数据,并维护数据被分片(chunk)并存储到分节点(chunkservers)的地址。Bayou 是一个分布式关系数据库系统,允许断线(disconnected)操作,并提供最终的数据一致性 [21]。
在这些系统中,Bayou、Coda 和 Ficus 都支持断线的情况下进行操作,并对网络分区(network partitions )和中断( outages)等问题具有很强的弹性。这些系统的不同之处在于如何解决冲突。例如,Coda 和 Ficus 在系统层面解决,而 Bayou 是在应用层面。不过,它们都保证最终一致性。
与这些系统类似,Dynamo 允许在发生网络分区的情况下继续执行读写操作,并通过不同的冲突解决机制来处理更新冲突。分布式块存储系统(distributed block storage system),例如 FAB [18],将大对象分割成较小的块(block),并以高可用的方式存储。与之相比,我们的场景更适合使用KV存储,因为:(a)它的定位就是存储相对较小的对象(大小 < 1M);(b)KV存储更容易针对每个应用进行配置。Antiquity 是一个广域(wide-area)分布式存储系统,用于处理多个服务器故障 [23]。它使用一个安全的日志来保证数据完整性,复制日志到多个服务器以达到持久性,并使用拜占庭容错协议(Byzantine fault tolerance protocols,译者注,参见拜占庭将军问题)保证数据的一致性。相较于 Antiquity,Dynamo 是为一个受信任的环境所构建的,所以数据的完整性和安全性并不是我们关注的重点。Bigtable 一个管理结构化数据的分布式文件系统,它维护了一张稀疏的多维有序映射表(sparse, multi-dimensional sorted map),并允许应用通过多重属性 [2] 访问它们的数据。相较于 Bigtable,Dynamo 的目标应用只需要以 key/value 方式访问数据,并主要关注高可用性,即使是在网络分区或服务器故障时,更新操作都不会被拒绝。
传统的复制型关系数据库系统都强调保证保证数据 副本的强一致性。虽然强一致性给应用编写者提供了方便的编程模型,但是这些系统在可扩展性和可用性方面受到了限制 [7]。正因为需要提供强一致性保证,这些系统将不能处理网络分区。
3.3 讨论
与上述去中心化的存储系统相比,Dynamo 有着不同的目标需求。第一,Dynamo 主要针对那些需要“永远可写”数据存储的应用,更新操作不会因故障或并发写而被拒绝。这是 Amazon 许多应用的关键需求。第二,如前所述,Dynamo 是在一个假定所有节点都被信任的、单一管理域的基础设施之上构建的。第三,使用 Dynamo 的应用不需要分层化的命名空间(许多文件系统采用的规范),也不需要复杂的关系型 schema(传统数据库所支持)。第四,Dynamo是为延时敏感型应用程序设计的,至少99.9%的读写操作需要在几百毫秒内执行完成。为了满足这些严格的延时需求,就必须避免将请求在多节点之间进行路由的方式(这是一些分布式哈希表(distributed hash table,DHT)系统,如Chord和Pastry,采用的典型设计)。这是因为多跳(multi-hop)路由将增加响应时间的抖动性(variability),进而增加了高百分位的延迟。Dynamo可以被表述为零跳(zero-hop)的DHT,每个节点在本地维护了足够多的路由信息,能够将请求直接路由到合适节点。
4. 系统架构
运行在生产环境的存储系统,其架构是很复杂的。除了实际的数据持久化组件之外,系统还需要具有可扩展的健壮的解决方案,用于负载均衡、成员管理(membership)和故障检测、故障恢复、副本同步、过载处理、状态转移、并发和任务调度、请求编组(marshalling)、请求路由(routing)、系统监控和告警,以及配置管理。描述每个解决方案的细节是不可能的,因此本文主要关注 Dynamo 中使用的核心分布式系统技术:分区(partitioning)、复制(replication)、版本化(versioning)、成员管理(membership)、故障处理(failure handling)和扩展(scaling)。表1 总结了 Dynamo 使用的技术及其各自的优点。
| Problem | Technique | Advantage |
|---|---|---|
| Partitioning | Consistent Hashing | Incremental Scalability |
| High Availability for writes | Vector clocks with reconciliation during reads | Version size is decoupled from update rates. |
| Handling temporary failures | Sloppy Quorum and hinted handoff | Provides high availability and durability guarantee when some of the replicas are not available. |
| Recovering from permanent failures | Anti-entropy using Merkle trees | Synchronizes divergent replicas in the background. |
| Membership and failure detection | Gossip-based membership protocol and failure detection. | Preserves symmetry and avoids having a centralized registry for storing membership and node liveness information. |
表 1:Dynamo 中使用的技术及其优点的总结。
4.1 系统接口
Dynamo 通过一个简单的接口存储键值对象;它提供两个操作:get() 和 put() 。get(key) 方法定位到存储系统中 key 对应的对象副本,并返回单个对象或一个包含冲突的版本的对象列表,以及上下文(context)。put(key, context, object) 方法根据对应的 key 确定副本应该存放的位置,并将其写入磁盘。上下文编码了对调用者不透明的对象的系统元数据,还包含了诸如对象版本的一些信息。上下文信息是跟对象一起存储的,以便系统可以验证 put 请求中提供的上下文对象是否有效。
Dynamo 将调用者提供的 key 和对象都视为不透明的字节数组。它使用 MD5 哈希将 key 生成一个128位的标识符(id),并使用 id 来确定负责该 key 的存储节点。
4.2 分区(Partitioning)算法
Dynamo 的关键设计要求之一是它必须支持增量扩展。这就需要一种机制来将数据动态划分到系统中的不同节点(例如,存储主机)上。Dynamo 的分区方案依赖于一致性哈希(consistent hashing)将负载分发到多个存储主机。在一致性哈希 [10] 中,哈希函数的输出范围被视为一个固定的圆形空间或称为“环”(即,最大 hash 值与最小 hash 值在环内首尾相接)。系统中的每个节点(译者注,服务器)都在这个空间中被分配了一个随机值,表示其在环上的“位置”。通过 hash 函数计算出数据项的 key 在环上的分布位置,然后顺时针遍历环以找到第一个位置大于该项位置的节点,从而将由 key 标识的每个数据项分配给节点。因此,每个节点负责环中当前节点与环上的前一个节点之间的区域。一致性哈希的主要优点是节点的添加或删除只会影响相邻的节点,而其他节点不受影响。
基础的一致哈希算法还存在一些问题。首先,环上每个节点的位置是随机分配的,这会导致数据和负载不能均匀分布。其次,基础的算法忽视了节点间性能的不同。为了解决这些问题,Dynamo 使用了一致性哈希的一个变体(类似于 [10,20] 中使用的哈希):每个节点不是映射到环上的一个单点,而是多个点。为此,Dynamo 使用了“虚拟节点”(virtual node)的概念。一个虚拟节点看上去和系统中一个普通节点一样,但每个节点是可以负责多个虚拟节点的。实际上,当一个新的节点添加到系统后,它会在环上被分配多个位置(以下简称“token”)。Dynamo 分区方案的进一步调优将会在Section 6 讨论。
使用虚拟节点有以下优点:
如果一个节点变得不可用(由于故障或例行维护),这个节点处理的负载将均匀分散在剩余的可用节点上。
当一个节点再次可用,或者向系统添加一个新节点时,新可用节点从其他每个可用节点接受大致相等的负载。
一个节点负责的虚拟节点的数量可以根据其容量决定,从而解决物理基础架构中的异构性。
4.3 复制(Replication)
为了实现高可用性和持久性,Dynamo 将数据复制到多台机器上。每个数据项会被复制到 N 台机器,其中 N 是配置项 “per-instance” 的参数。每个 key k,会被分配一个 coordinator节点(前面章节所述)。coordinator节点掌控其负责范围内的数据的复制。它除了在本地存储其范围内的每个 key 外,还会复制到环上顺时针方向的 N-1 个后继节点。这导致了系统中,每个节点要负责从它自己往后的一共 N 个节点。在图2中,节点 B 除了在本地存储 key k 外,还会将其复制到 C 和 D 节点。节点 D 将存储落在(A,B]、(B,C] 和 (C,D] 范围 上的所有 key。
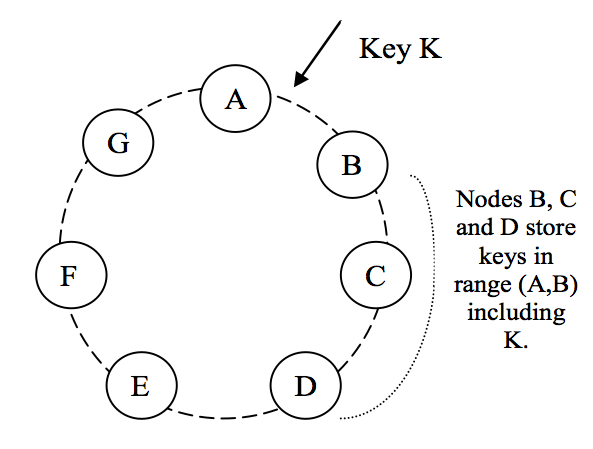
图 2:Dynamo 环中 key 的分区和复制。
负责存储特定 key 的节点列表称为优先列表(preference list)。该系统的设计是,正如将在 Section 4.8 中进行说明的,对于任何特定的 key,系统中的每个节点都可以决定哪些节点应该在这个列表中。为了应对节点故障的情况,优先列表会包含超过 N 个节点。需要注意的是,在使用虚拟节点时,存储一个 key 的 N 个后继节点,实际上对应的物理节点可能少于 N 个(即一个节点可能拥有前N个位置中的不止一个位置)。为了解决这个问题, key 的优先列表在构建时会跳过环上的一些位置,以确保该列表只包含不同的物理节点。
4.4 数据版本化(Data Versioning)
Dynamo 提供最终一致性,允许将更新操作异步地传递给所有的副本。put() 调用可能在数据更新应用于所有副本之前返回给调用者,这可能导致后续 get() 操作获取不到最新数据。在没有故障的情况下,更新操作的传递时间有一个上限。但是,在某些故障场景下(例如,服务器宕机或网络分区),更新操作可能在很长一段时间内无法到达所有的副本。
Amazon 平台上有一类应用是可以容忍这种不一致性的,并且可以在这种条件下运行。例如,购物
车应用程序要求“添加到购物车”的请求永远不能被遗漏或拒绝。如果购物车的最新状态不可用,而用户对较旧版本的购物车进行了修改,那么该修改仍然有意义,应该保留。但同时它不应直接替代当前购物车不可用的状态,因为这不可用的状态中可能也有一些修改需要保留。需要注意的是,不
管是“添加到购物车”还是“从购物车删除”操作,都会被转换成是 Dynamo 的 put() 请求。当用户想要向购物车中添加(或从购物车中删除)某个商品,而最新版本又不可用时,该商品将被添加到旧版本(或从旧版本中删除),并由随后的步骤来协调处理更新冲突。
为了提供这种保证,Dynamo 将每次修改结果都视为一个新的、不可变的数据版本。它允许一个对象的多个版本同时出现在系统中。大多数情况下,新版本都包含老版本的数据,而且系统自己可以判断哪个是权威版本(syntactic reconciliation,语法协调)。然而,在故障与并发更新并存的情况下,可能会发生版本分叉(version branching),从而导致对象的版本冲突。在这种情况下,系统无法协调同一对象的多个版本,客户端必须执行协调,以便将数据演化的多个分支重新合并成一个(semantic reconciliation,语义协调)。一个典型的例子是”合并“用户购物车的多个不同版本。使用这种协调机制,”添加到购物车”操作就永远不会失败。但是,删除的商品可能会重新出现在购物车中。
需要重点留意的是,某些故障模式(failure mode)会导致系统拥有不止两个而是多个版本的相同数据。在存在网络分区和节点故障的情况下进行更新,可能会导致对象具有不同的版本子历史(sub-histories),需要系统在未来对此进行协调。这要求我们设计的应用程序明确承认同一数据的多版本存在的可能性(以便永远不会丢失任何更新)。
Dynamo 使用矢量时钟(vector clock)[12] 来捕捉同一对象不同版本之间的因果关系。矢量时钟实际上是一个 (node, counter) 列表。一个矢量时钟与每个对象的每个版本相关联。通过检查其矢量时钟,我们可以判断一个对象的两个版本是否在并行的分支上,或者是否有因果关系。如果第一个对象时钟上的计数器小于或等于第二个时钟中的所有节点,那么第一个时钟就是第二个的祖先,可以安全地删除。否则,这两个修改就被认为是有冲突的,需要协调冲突。
在 Dynamo 中,当客户端想要更新一个对象时,它必须指定将基于哪个版本进行更新。这是通过传递它从前面的读操作中获得的上下文来实现的,其中上下文包含矢量时钟信息。在处理读请求的时候,如果 Dynamo 访问到多个不能语法协调(syntactically reconciled)的版本分支,它将返回叶子上的所有对象,以及上下文中相应的版本信息。使用此上下文的更新被认为已经协调了不同的版本,多个分支被合并为一个唯一的新分支。
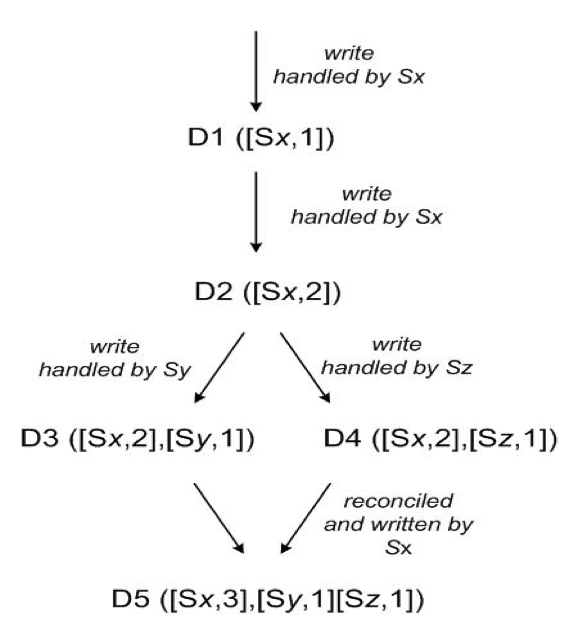
图 3:对象随时间的版本演化。
为了说明矢量时钟的使用,让我们考虑图3所示的例子。首先,客户端写入一个对象。处理这个 key 的写操作的节点(比如说 Sx)递增序列号,并用此创建对象的矢量时钟。至此系统拥有了对象 D1 及其对应的时钟 [(Sx, 1)] 。第二步,客户端更新该对象。假定还是由相同的节点处理这个请求。现在该系统也拥有了对象 D2 及其对应的时钟 [(Sx, 2)]。D2继承自D1,因此覆盖了D1,但是节点中或许存在还没有看到D2的D1的副本。第三步,让我们假设还是这个客户端再次更新了对象,但是由另一个服务器(比如Sy)处理该请求。现在该系统拥有了数据 D3 及其对应的时钟 [(Sx, 2),(Sy, 1)]。
接下来,假设另一个客户端读取 D2 并试图更新它,另一个节点(比如Sz)执行写入操作。系统现在有 D4(D2 的后代),其版本时钟是 [(Sx, 2),(Sz, 1)]。一个能意识到 D1 和 D2 存在的节点,在收到 D4 及其时钟时,能够确定 D1 和 D2 被这个新数据覆盖了,因此可以被垃圾回收掉。一个能意识到 D3 存在的节点,在接收D4时将会发现,它们之间不存在因果关系。换句话说,D3 和 D4 各自的改动并没
有反映在对方之中。因此这两个版本都应当被保留并提交给客户端,由客户端(在读时)执行语义协调。
现在假设一些客户端同时读取到了 D3 和 D4(上下文将反映是在读操作时找到了这两个值)。读操作返回的上下文综合了 D3 和 D4 的时钟,即 [(Sx, 2), (Sy, 1), (Sz, 1)]。如果客户端执行协调,且由节点 Sx 来协调这个写操作,Sx 将更新其时钟的序列号。新的数据 D5 将有以下时钟:[(Sx, 3), (Sy, 1), (Sz, 1)]。
关于矢量时钟的一个潜在问题是,如果许多服务器协调对一个对象的写,矢量时钟的大小可能会增长。实际上,这不太可能,因为写操作通常由优先列表中的前 N 个节点之一来处理。只有在网络分区或多个服务器故障的情况下,写请求才可以由不在优先列表的前N个的节点处理,从而使矢量时钟的大小增加。在这些情况下,最好限制矢量时钟的大小。为此,Dynamo 使用以下时钟截断方案(clock truncation scheme):伴随着每个 (node, counter) 对,Dynamo 存储一个时间戳记录节点更新数据项的最后一次时间。当矢量时钟中 (node, counter) 对的数目达到一个阈值(如 10),最早的一对将从时钟中删除。显然,由于无法精确地导出后代关系,这种截断方案可能导致和解效率低下。然而,这个问题还没有在生产中出现,因此这个问题还没有得到彻底的调查。
4.5 get() 和 put() 的执行过程
Dynamo 中的任何存储节点都有资格接收客户端的任何对 key 的 get 和 put 操作。为了简单起见,本节我们将描述如何在无故障环境中执行这些操作,在下一节中,我们将描述如何在故障期间执行读写操作。
get 和 put 操作都是使用 Amazon 特定于基础设施的请求处理框架,并通过 HTTP 调用的。客户端有两种策略来选择节点:(1)通过一个普通的负载均衡器路由其请求,该负载均衡器将根据负载信息选择一个节点;(2)使用一个分区敏感(partition-aware)的客户端库,直接将请求路由到适当的 coordinator 节点。第一种方式的好处是客户端不必在其应用程序中链接(link)任何 Dynamo 相关的代码,第二种的好处是可以实现较低的延时,因为它跳过了一次潜在的转发步骤。
处理读或写请求的节点被称为 coordinator。通常,这是优先列表(preference list)中前 N 个节点中的第一个。如果通过负载均衡器接收请求,访问某个 key 的请求可能被路由到环上任意一个节点。在这种情况下,如果接收到请求的节点不在被请求的 key 的优先列表的前N个节点中,那它就不会处理这个请求。相反,该节点会将请求转发到优先列表前 N 个节点中的第一个。
读写操作涉及优先列表中的前 N 个健康节点,跳过那些宕机或不可访问的节点。当所有节点都健康时,将访问优先列表中前 N 个节点。当存在节点故障或网络分区时,将访问优先列表中编号较小的节点。
为了维护副本的一致性,Dynamo 使用了一种与仲裁系统(quorum systems)中所使用的类似的一致性协议。该协议有两个关键配置参数:R 和 W。R 是成功完成一次读操作所需的最小节点数。W 是成功完成一次写操作所需的最小节点数。设置 R 和 W,使 R + W > N,就得到了一个类似仲裁的系统。在此模型中,一次 get(或 put)操作的延迟是由 R(或 W)副本中最慢的一个决定。因此,R 和 W 通常被配置为小于 N,以提供更好的延迟。
在收到一个 key 的 put() 请求后,coordinator 会为新版本生成矢量时钟,并将新版本写入本地。然后,coordinator 将新版本(及新的矢量时钟)发送到 N 个排在最前面的可达节点。如果至少有 W-1 节点响应,则认为写入成功。
类似地,对于一个 get() 请求,coordinator 会从 N 个排在最前面的可达节点请求该 key 所有现存的数据版本,等待 R 个响应之后,返回结果给客户端。如果coordinator 最终收集了多个版本的数据,它将返回所有它认为没有因果关系的版本。不同版本将被协调,并将取代当前版本的协调版本写回。
4.6 故障处理:提示移交(Hinted Handoff)
如果 Dynamo 使用传统的仲裁方法,那么在服务器故障和网络分区期间它将不可用,并且即使在最简单的故障情况下也会降低持久性。为了弥补这一点,它不严格执行仲裁,而是使用“草率的仲裁”(sloppy quorum);所有读和写操作都是在优先列表的前 N 个健康节点上执行的,它们可能不总是在散列环上遇到的前 N 个节点。
考虑图 2 中 Dynamo 的配置示例,其中 N=3。在本例中,如果节点 A 在写操作期间临时关闭或无法访问,那么通常存在于 A 上的一个副本现在将发送到节点 D。这样做是为了保证期望的可用性和持久性。发送到 D 的副本的元数据中会有一个提示(hint),表明哪个节点是副本的预期接收者(在本例中为 A)。含提示的副本将被接收节点保存在一个单独的本地数据库中,并定期扫描。在检测到 A 已恢复后,D 将尝试将副本发送回 A。发送成功后,D 将从本地数据库中将其删除,从而不会降低系统中的副本总数。
使用 hinted handoff,Dynamo 能确保读写操作不会因为节点或网络临时故障而失败。应用如果需要最高的可用性,可以将 W 设为 1,这就保证了只要系统中有一个节点将 key 持久地写入到本地存储,这次写操作就被接受了。因此,只有当系统中的所有节点都不可用时,写请求才会被拒绝。然而实际上,在生产环境中大部分 Amazon 的服务都将 W 设置得较大,以满足期望的持久性要求。Section 6将更详细地讨论 N、R 和 W 的配置。
一个高可用性的存储系统必须具备处理整个数据中心故障的能力。断电、冷却系统故障、网络故障和自然灾害都会导致整个数据中心发生故障。Dynamo 可以配置成每个对象都可以跨多个数据中心复制。本质上,一个 key 的优先列表是基于将存储节点分布到多个数据中心来构造的。这些数据中心之间通过高速网络连接。这种跨多个数据中心复制的方案允许我们在没有数据中断的情况下处理整个数据中心故障。
4.7 持久故障处理:副本同步(Replica synchronization)
在系统成员变动(churn)较低、节点故障很短暂的情况下,hinted handoff 能保证良好的工作。在某些情况下,在 hinted 副本移交回原来的副本节点之前,该副本就不可用了。为了解决这个问题,以及其他对持久性的威胁,Dynamo实现了一个反熵(anti-entropy,或称副本同步)协议来保持副本同步。
为了更快地检测副本之间的不一致性,以及最小化传输的数据量,使用了 Merkle 树 [13]。Merkle 树是一种哈希树,其中叶子节点是各个 key 的哈希值。树中较高的父节点是其子节点的哈希。Merkle 树的主要优点是可以独立检查树的每个分支,而无需节点下载载整个树或整个数据集。此外,Merkle 树有助于减少在检查副本之间的不一致性时所需传输的数据量。例如,如果两树根节点的哈希值相等,那么树中的叶子节点的值也相等,此时节点之间就不需要同步。如果不相等,则意味着某些副本的值是不同的。在这种情况下,两台节点就需要交换子节点的哈希值,这个过程一直持续到到达叶子节点,此时就可以识别出“不同步”的 key。Merkle 树最小化了同步所需传输的数据量,并减少了在反熵过程中执行的磁盘读取次数。
Dynamo 使用 Merkle 树实现反熵的过程如下:每个节点为每段 key range(一个虚拟节点所覆盖的 key 的集合)维护了一个单独的 Merkle 树。这允许节点之间可以比较 key range 内的 key 是否是最新的。在这个方案中,两个节点会交换他们都有的 key range 所对应的 Merkle 树的根节点。随后,使用上面描述的树遍历方案,节点可以判断它们是否有任何差异,并执行适当的同步操作。这种方案的缺点是,当有节点加入或离开系统时有许多 key range 会改变,从而需要重新对树进行计算。不过,这个问题可以通过第 6.2 节中描述的改进分区方案(partitioning scheme)来解决。
4.8 成员管理和故障检测
4.8.1 哈希环成员(Ring Membership)
在 Amazon 的环境中,节点中断(由于故障和维护任务)通常情况下是暂时的,但也可能出现中断比较长的情况。一个节点中断少意味着这个节点永久性的离开了系统, 因此不应该导致 partition 分配的重新平衡或者修复无法访问的副本。同样,人工错误可能导致新的 Dynamo 节点的意外启动。因此,应当使用一个明确的机制来发起从Dynamo环中添加和删除节点。管理员使用命令行工具或浏览器连接到一个 Dynamo 节点,并下发成员变动(membership change)命令从环中加入或删除一个节点。负责处理这个请求的节点将成员变动及其对应的时间写入持久存储。成员变动会形成历史记录,因为一个节点可以被多次删除和重新添加。
一个基于 Gossip 的协议传播成员变动消息,并维护一份最终一致的成员关系视图。每个节点每秒会随机选择一对等节点进行通信,这两个节点会高效地协调他们持久化的成员变动历史。
当一个节点第一次启动时,它会选择它的 token 集(一致性哈希空间内的虚拟节点 ),并将节点映射到各自的 token 集。该映射关系会被持久化到磁盘上,最初只包含本地节点和token 集。存储在不同 Dynamo 节点上的映射关系,将在协调成员变动历史的通信过程中一同被协调。因此,分区(partitioning)和位置(placement)信息也通过基于 Gossip 的协议传播,每个存储节点都知道其对等节点处理的 token 范围。这使得每个节点可以将一个 key 的读/写操作直接发送给正确的节点集。
4.8.2 外部发现(External Discovery)
上述机制可能会暂时导致 Dynamo 环的逻辑分区。例如,管理员可以先联系节点 A 将其加入到环,然后联系节点 B 将其加入到环。在这种情况下,节点 A 和 B 都会认为自己是环的一员,但都不会立即感知到对方。为了避免逻辑分区,一些 Dynamo 节点充当种子节点的角色。种子是通过外部机制(external mechanism)发现的节点,所有节点都知道它的存在。因为所有节点最终都会和种子节点协调成员信息,所以逻辑分区就几乎不可能发生了。种子可以从静态配置文件或者从一个配置中心获取。通常,种子节点具有 Dynamo 环上节点的全部功能。
4.8.3 故障检测(Failure Detection)
Dynamo 中的故障检测被用于避免,在 get() 和 put() 操作期间以及在传输分区和提示副本(hinted replica)时,尝试与不可到达的对等节点通信。为了避免通信失败的尝试,一个纯本地概念(pure local notion)的故障检测完全足够了:如果节点 B 没有响应节点 A 的消息(即使 B 可以应答 C 的消息),节点 A 可能会认为节点 B 故障。在 Dynamo 环中,当客户端请求以稳定的速率产生节点间通信时,一旦节点 B 无法对消息做出应答,节点 A 就能很快发现 B 不响应;然后节点 A 使用备用节点处理映射到 B 的分区的请求;A 定期重试 B,检查其是否恢复。在没有客户端请求来驱动两个节点之间的通信时,两个节点实际上都不需要知道另一个节点是否可访问和可响应。
去中心化故障检测协议使用简单的 Gossip 风格协议,使系统中的每个节点都可以感知到其他节点的加入(或离开)。有关去中心化的故障探测器和影响其准确性的参数的详细信息,感兴趣的读者可以参考 [8]。Dynamo 的早期设计中使用了去中心化的故障检测器来维护一个故障状态的全局一致视图 。后来发现,显式的节点加入和离开机制使得故障状态的全局视图变得多余了。这是因为,通过显式的节点加入和离开机制,节点可以感知其他节点持久性的添加和删除;而短暂的节点故障,可以在个别节点(转发请求时)无法与其他节点通信时被检测到。
4.9 添加/移除存储节点
当一个新节点(比如 X)被添加到系统中时,它会被分配一些随机分布在环上的 token。对于每个分配给节点 X 的 key range,可能有一些节点(小于等于 N 个)当前已经在处理落在其 token range内的 key 了。由于将 key range 分配给了 X ,这些节点就不需要这些 key 了,而是将这些 key 转给 X。让我们考虑一个简单的引导(bootstrapping)场景,节点 X 被添加到图 2 所示环中的 A 和 B 之间。当 X 添加到系统后,它负责的 key 的范围为 (F, G],(G, A] 和 (A, X]。这样,节点 B、C 和 D 就不再需要将 key 存储在各自的范围内了。因此,在收到 X 确认后,B、C 和 D 会向 X 传输相应的 key。当从系统中删除一个节点时,key 的重新分配将以相反的过程进行。
实际运行经验表明,这种方法可以将 key 分布的负载均匀地分布在各个存储节点上,这对于满足延迟需求和确保快速引导(bootstrapping )是非常重要的。最后,通过在源和目标之间增加一轮确认,可以确保目标节点不会重复收到任何给定 key range。
5. 实现
在 Dynamo 中,每个存储节点有三个主要的软件组件:请求协调、成员和故障检测,以及一个本地持久存储引擎。所有这些组件都是 Java 实现的。
Dynamo 的本地持久化存储组件支持插入不同的存储引擎。在使用的引擎包括:Berkeley Database (BDB) Transactional Data Store、BDB Java Edition、MySQL 和一个持久化备份存储的内存缓冲区。将其设计为一个可插拔的持久化组件的主要原因,是为了能根据应用程序的访问模式选择最适合的存储引擎。例如,BDB 通常可以处理几十 KB 的对象,而 MySQL 可以处理更大的对象。应用可以根据自己对象大小的分布选择合适的 Dynamo 本地持久化引擎。大多数 Dynamo 的生产实例都使用 BDB Transactional Data Store。
请求协调组件是构建在一个事件驱动的消息系统的基础之上的,其中消息处理 pipeline 被分成多个阶段,类似于 SEDA 架构 [24]。所有通信都基于 Java NIO channel 实现。coordinator 通过从一个或多个节点收集数据(读操作时),或向一个或多个节点存储数据(写操作时),从而代替客户端执行读写请求。每个客户端请求都会在收到这个请求的节点上创建一个状态机(state machine)。状态机包含识别 key 对应的节点、发送请求、等待响应、可能的重试处理、处理响应并将响应打包到客户机的所有逻辑。每个状态机实例只处理一个客户机请求。例如,一个写操作实现了以下状态机:(1)发送读请求到节点;(2)等待所需的最少数量响应;(3)如果在给定上限的时间内收到的响应数量太少,请求失败;(4)否则,收集所有数据的版本,并确定要返回的版本;(5)如果启用了版本控制,执行语法协调(syntactic reconciliation),并生成一个不透明的写上下文(write context),其中包含了所有剩余版本的矢量时钟。为了简单起见,省略了故障处理和重试状态。
读操作的响应发送给调用方之后,状态机将继续等待一小段时间,以接收任何未完成的响应。如果任何响应返回了过期版本,coordinator将使用最新版本更新这些节点。这个过程被称为读修复(read repair),因为它借此时机修复了那些错过了最新更新的副本,减少了反熵协议的操作。
如前所述,写请求是由优先列表中某个排名前 N 的节点来协调的。尽管总是选择前 N 节点中的第一个节点来协调是满足需要的,这样可以在一个位置将所有的写操作序列化,但是这种做法却会导致负载分布不均匀,从而违反了 SLA。这是因为请求负载不是均匀分布在对象之间的。为了解决这个问题,优先列表中的任何前 N 个节点都被允许协调写操作。特别是,由于每次写操作通常跟随在一个读操作之后,因此写操作的 coordinator 通常选择用存储在请求上下文信息中的前一次读操作响应最快的节点。这项优化使我们能够选中那个被前一次读操作读取过数据的节点,从而提高了达成 “read-your-writes” 一致性的概率。同时,这还降低了请求处理性能的抖动性,提高了 99.9 百分位点的性能。
6. 经验与教训
Dynamo 被几个具有不同配置的服务所使用。这些实例有着不同的版本协调逻辑和读/写仲裁(quorum)的特性。以下是 Dynamo 的主要使用模式:
业务逻辑特定的协调:这是 Dynamo 的一个流行用例。每个数据对象被复制到多个节点。当发生版本冲突时,客户端应用程序执行自己的协调逻辑。前面讨论的购物车服务就是这一类的典型例子。其业务逻辑是通过合并用户购物车的不同版本来协调对象。
基于时间戳的协调:这种情况与前面相比只是和解机制不同。当发生版本冲突时,Dynamo 执行简单的基于时间戳的协调逻辑:“最后一次写胜出”(last write wins);例如,选择物理时间戳值最大的对象作为正确版本。该模式一个典型的例子是维护客户 session 信息的服务。
高性能读引擎:虽然 Dynamo 被设计为一个“永远可写”(always writeable)的数据存储,但也有一些服务通过调整其仲裁(quorum)特性把它作为一个高性能读引擎来使用。通常,这些服务具有较高的读取请求速率但只有少量更新。在这种配置中,通常将 R 设为 1,W 设为 N。对于这些服务,Dynamo 提供了跨多个节点进行数据分区(partition)和复制的能力,从而提供了增量可扩展性。其中一些实例作为权威持久缓存(authoritative persistence cache),来缓存存储在更重量级的后端存储中的数据。
Dynamo 的主要优点是它的客户端应用可以通过对 N、R 和 W 三个参数进行调优来达到期望的性能、可用性和持久性水平。例如,N的值决定了每个对象的持久性。Dynamo 用户使用的一个典型的 N 值是 3。
W 和 R 的值会影响对象的可用性、持久性和一致性。例如,如果 W 设置为 1,那么只要系统中至少还有一个节点可以成功处理写请求,那么写请求就不会被系统拒绝。不过,W 和 R 值较低会增加不一致的风险,因为写请求即使没有被大多数副本处理,仍然能够被视为成功并返回到客户端。当一次写请求即使只在少量节点上完成了持久化也会向客户端返回成功时,这也引入了一个持久性的风险窗口(vulnerability window)。
传统观点认为,持久性和可用性是密切相关的。然而,这里不一定是这样。例如,持久性的风险窗口可以通过增加 W 来减少。但这将增加请求被拒绝的机率(从而降低了可用性),因为这种情况下需要更多处于活动状态的存储主机来处理写请求。
Dynamo 的几个实例使用的常见 (N, R, W) 配置是 (3,2,2)。选择这些值是为了满足性能、持久性、一致性和可用性 SLA 的必要级别。
本节中介绍的所有数据都是从一套线上系统获得的,该系统的配置为 (3, 2, 2),运行着几百个具有相同硬件配置的节点。如前所述,Dynamo 的每个实例都包含位于多个数据中心的节点。这些数据中心通常是通过高速网络连接。回想一下,执行一次成功的 get(或 put)需要 R(或 W)个节点响应 coordinator 。显然,数据中心之间的网络延迟会影响响应时间,因此需要选择节点(及其数据中心位置)以满足应用程序的目标 SLA。
6.1 平衡性能和持久性(Performance and Durability)
虽然 Dynamo 的主要设计目标是建立一个高可用的数据存储,但性能也是在 Amazon 平台中同样重要的标准。如前所述,为了提供一致的用户体验,Amazon 的服务将性能目标设置为相对更高的百分位点(例如 99.9 或 99.99 百分位点)。Dynamo 中一个典型 SLA 是 99.9% 的读写请求在 300ms 内执行完成。
由于 Dynamo 运行在标准的商用硬件组件上,这些组件的 I/O 吞吐量远远低于高端企业级服务器,因此提供一致的高性能读写并不是一项简单的任务。多个存储节点参与读写操作使其更具挑战性,因为这些操作的性能是受 R 或 W 副本中最慢的副本限制的。图4显示了 30 天内 Dynamo 读写操作的平均延迟和 99.9 百分位的延迟。从图中可以看出,延迟表现出明显的日变化模式(diurnal pattern),这是因为传入请求的速率也是日变化模式的(例如,日间和夜间的请求速率有着显著差异)。另外,写延迟明显高于读延迟,因为写操作永远需要访问磁盘。同时可以看到,99.9 百分位延迟约为 200ms,比平均值高出一个数量级。这是因为 99.9 百分位的延迟受到几个因素,如请求负载、对象大小和位置模式(locality pattern)的变化影响。
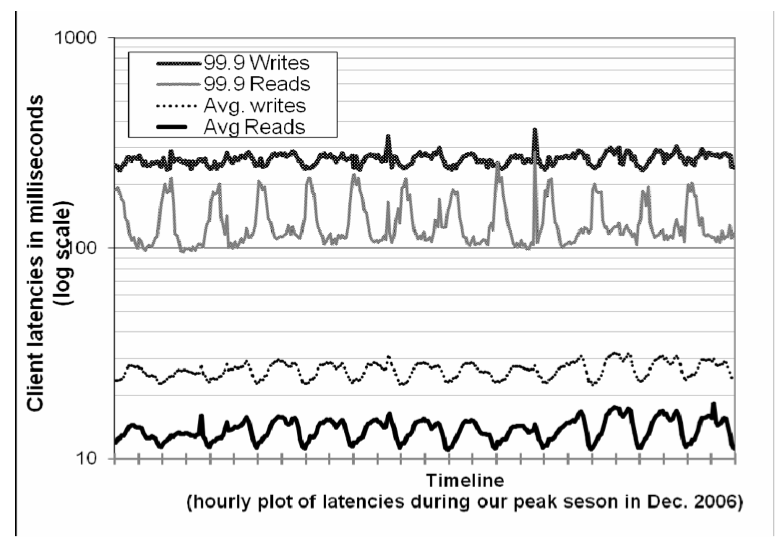
图 4:在 2006 年 12 月的请求高峰期,读写请求的平均延迟和 99.9 百分位延迟。x 轴上一个刻度为 12 小时。延迟遵循类似于请求率的日变化模式,并且 99.9 百分位延迟比平均值高一个数量级。
虽然这种性能水平对于很多服务是足够的,但是有些面向用户的服务对性能有着更高的要求。对于这些服务,Dynamo 能够牺牲持久性来保证性能。在这个优化中,每个存储节点会在主内存中维护一个对象缓冲区(buffer)。每个写操作都存储在 buffer 中,通过写线程定期将 buffer 写入存储。在此方案中,读取操作首先检查请求的 key 是否存在于缓冲区中。如果是,则从缓冲区而不是存储引擎读取对象。
这项优化使得高峰流量期间 99.9 百分位的延迟降低到原来的 1/5,即使是对于一个非常小的包含1000个对象的缓冲区(见图 5)。此外,如图中所示,写缓冲(write buffering)可以使较高百分位的延迟曲线变得平滑。显然,该方案是平衡持久性来提高性能的。在此方案中,服务崩溃可能会导致缓冲区队列中等待写入的数据丢失。为了降低持久性风险,将写操作细化为让 coordinator 从 N 个副本中选择一个进行“持久化写入”。因为 coordinator 只等待 W 个写操作响应,所以整体写操作性能不受单个副本执行持久写操作的性能的影响。
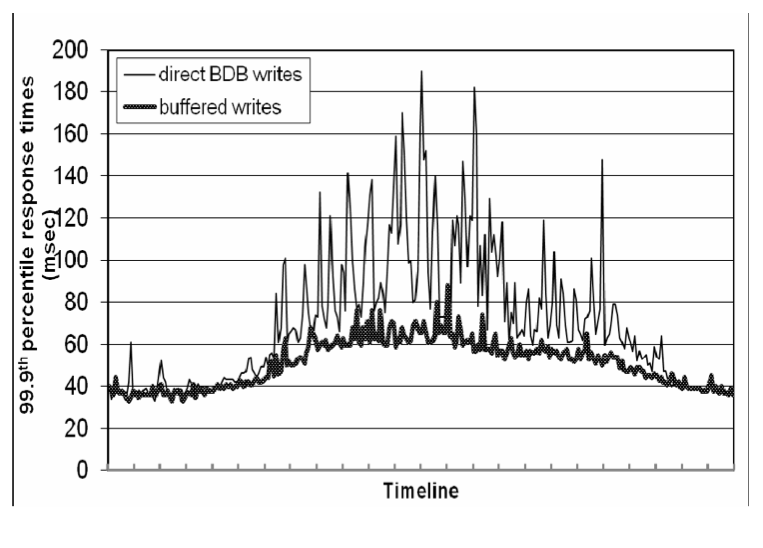
图 5:在 24 小时内,缓冲写与非缓冲写之间 99.9 百分位延迟的性能比较。x 轴上一个刻度为一小时。
6.2 确保均匀的负载分布(Uniform Load distribution)
Dynamo 使用一致性哈希将它的 key 空间在多个副本上进行分区(partition),以确保均匀的负载分布。假设key 的访问分布不是极度不平衡的,那么均匀的 key 分布就可以帮助我们实现均匀的负载分布。特别地,Dynamo 设计假定即使访问的分布存在明显的倾斜,只要在分布的热点端(popular end)有足够多的 key,同样可以通过分区实现处理热点 key 的负载均匀地分布到节点上。本节讨论 Dynamo 中所出现负载不均衡以及不同的分区策略对负载分布的影响。
为了研究负载不平衡及其与请求负载的关系,我们测量了每个节点在24小时内接收的请求总数,并将其划分为30分钟的间隔。在给定的时间窗口中,如果节点的请求负载与平均负载相差小于某个阈值(这里是 15%),则节点被认为是“平衡”(in-balance)的。否则该节点将被视为“不平衡”(out-of-balance)。图 6 展示了这段时间内“不平衡”节点的比例(以下简称“不平衡比例” - imbalance ratio)。为了便于参考,还绘制了这段时间内整个系统接收到的相应请求负载。从图中可以看出,不平衡比例随着负载的增大而减小。例如,低负载期间的不平衡比例高达 20%,而高负载期间降到了近 10%。直观上这可以解释为,在高负载下大量的热点 key 被访问时,由于 key 的均匀分布,负载也会平衡分布。然而,在低负载(负载是已测量峰值负载的八分之一)期间,只有很少的热点 key 被访问,从而导致更高的负载不平衡。
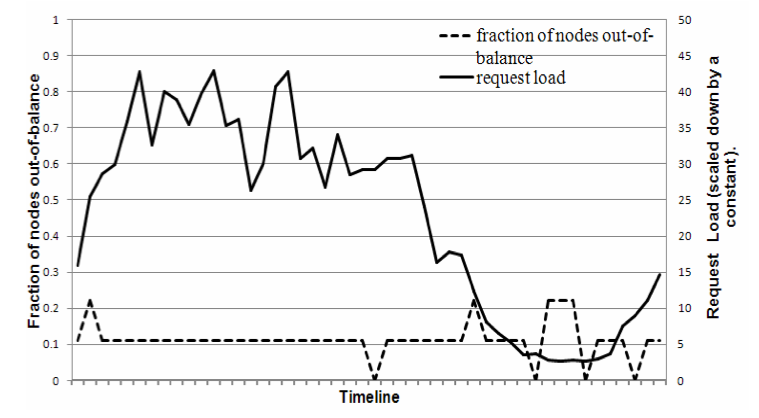
图 6:不平衡节点的比例(即,请求负载高于平均系统负载的某个阈值的节点)及其相应的请求负载。x 轴上一个刻度为 30 分钟。
策略 1:每个节点 T 个随机 token,按 token 值分区
这是部署在生产环境中的初始策略(在第 4.2 节介绍过)。在这个方案中,每个节点被分配 T 个 token(从哈希空间随机均匀地选择)。所有节点的 token 按照其在哈希空间中的值进行排序。相邻的两个 token 定义一个范围。最后一个 token 和第一个 token 组成一个范围,将哈希空间中的最大值和最小值“包装”起来。因为 token 是随机选择的,所以范围的大小不同。当有节点加入或离开系统时,token 集发生变化,导致范围范围也会更改。注意,维护每个节点的成员关系所需的空间随系统中节点的数量线性增加。
在使用此策略时,遇到了以下问题。第一,当一个新节点加入系统时,它需要从其他节点“窃取”其所需的 key range。然而,将 key range 移交给新节点的节点必须扫描其本地持久存储,以检索出适当的数据项集合。需要注意的是,在生产环境环境执行这种扫描操作是很棘手的,因为扫描是高度资源密集型的操作,为了不影响客户性能,需要在后台执行。这要求我们必须将新节点加入的引导任务(bootstrapping task)的优先级务调到最低。然而,这明显减慢了引导过程,尤其是购物高峰季节点每天处理数百万个请求时,引导过程几乎要花费一天的时间来完成。第二,当一个节点加入/离开系统时,许多节点处理的 key range 会发生变化,需要重新计算用于新范围的 Merkle 树,对于生产环境来说,这也不是一项简单的工作。最后,由于 key range 的随机性,无法方便地对整个 key 空间进行快照,这使得归档过程非常复杂。在这个方案中,归档整个 key 空间需要我们分别从每个节点检索 key,这是非常低效的。
这个策略的根本问题是,数据分区(partitioning)和数据安置(placement)的方案混在了一起。例如,在某些情况下,为了处理请求负载的增加,最好向系统添加更多的节点。但是,在这个场景中,不可能在不影响数据分区的情况下添加节点。理想情况下,最好使用独立的分区和安置方案。为此,我们评估了以下的策略:
策略 2:每个节点 T 个随机 token,大小相等的分区
在此策略中,将哈希空间划分为 Q 个大小相等的分区/范围,每个节点分配 T 个随机 token。Q 通常设置为 Q >> N 和 Q >> S*T,其中 S 为系统节点数。在此策略中,token 仅用于构建将哈希空间中的值映射到有序节点列表的函数,而不不决定分区。一个分区(partition)是放置在从该分区的末尾开始顺时针遍历一致性hash环遇到的前N个独立的节点上。图 7 展示了当 N=3 时这一策略的情况。在本例中,节点 A、B、C 是在从包含 key k1 的分区的末尾遍历环时遇到的。这种策略的主要优点是:(1)将数据的分区和分区安置解耦;(2)允许在运行时更改安置方案。
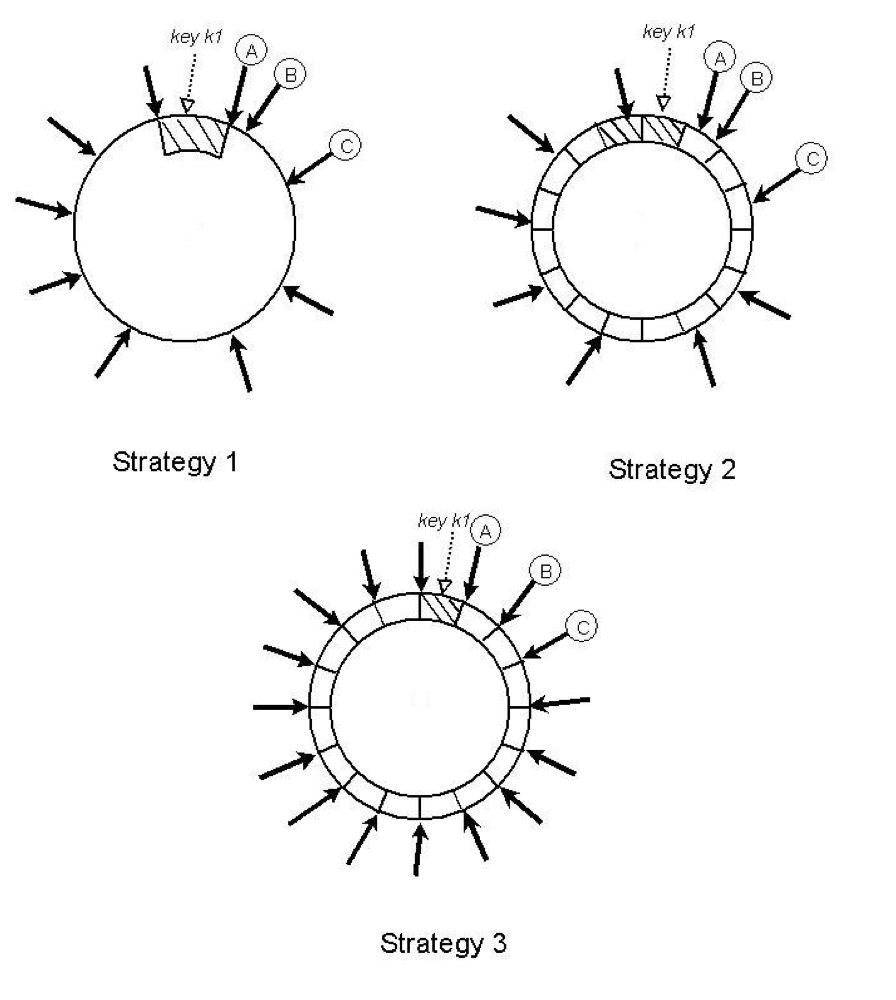
图 7:这三种策略中 key 的分区和安置。N=3,A、B 和 C 是在一致哈希环上构成 key k1 优先列表的三个独立节点。阴影区域表示节点 A、B 和 C 所构成的优先列表的 key range。黑色箭头表示各个节点的 token 位置。
策略 3:每个节点 Q/S 个 token,大小相等的分区
和策略 2 类似,该策略将哈希空间划分为大小相等的 Q 个分区,分区安置(placement of partition)与分区(partitioning)方案解耦。此外,每个节点都被分配 Q/S 个 token,其中 S 为系统节点数。当一个节点离开系统时,它的 token 会随机地分配给其他节点,以便保留这些属性。同样,当节点加入系统时,新节点将通过一种可以保留这种属性的方式从系统的其他节点“窃取” token。
使用一个配置为 S=30 和 N=3 的系统,评估这三种策略的效率。然而,由于不同的策略使用不同的配置对效率进行调优,因此很难公平地比较这些不同的策略。例如,策略 1 的负载分布特性取决于 token 的数量(即 T),而策略 3 取决于分区的数量(即 Q)。一个公平的比较方式是,在所有的策略都使用相同大小的空间维护成员信息时,测量它们的负载分布倾斜度(skew)。例如,在策略 1 中,每个节点需要维护环中所有节点的 token 位置,而在策略 3 中,每个节点需要维护分配到每个节点的分区有关的信息。
在下一个实验中,我们通过改变相关的参数 (T 和 Q) 对这些策略进行了评估。每个策略的负载均衡效率(load balancing efficiency )是根据每个节点需要维持的成员信息的大小的不同来测量,其中负载平衡效率是指每个节点服务的平均请求数与最热(hottest)节点服务的最大请求数之比。
结果如图 8 所示。从图中可以看出,策略 3 的负载均衡效率最好,策略 2 的负载均衡效率最差。在很短的时间内,策略 2 充当了将 Dynamo 实例从使用策略 1 迁移到使用策略 3 过程中的过渡策略。和策略 1 相比,策略 3 性能更好,并且在每个节点需要维持的信息的大小降低了三个数量级。虽然存储不是一个主要问题,但节点间会周期地 Gossip 成员信息,因此保持这些信息越紧凑越好。此外,策略3有利于且易于部署,原因包括:(1)更快的引导(bootstrapping)/恢复(recovery):由于分区范围是固定的,因此可以将其存放到单独的文件,这意味着一个分区可以作为一个整体通过转移文件被重新安置(避免了为定位特定数据而进行的随机访问)。这简化了引导和恢复的过程。(2)易于存档:定期对数据集进行存档是大多数 Amazon 存储服务的强制性要求。相反,在策略 1 中,token 是随机选取的,存档的时候需要从所有节点分别获取它们存储的 key 信息,这通常是低效和缓慢的。策略3的缺点是,更改节点成员关系时需要协调(coordination),以便维护分配所需的属性。
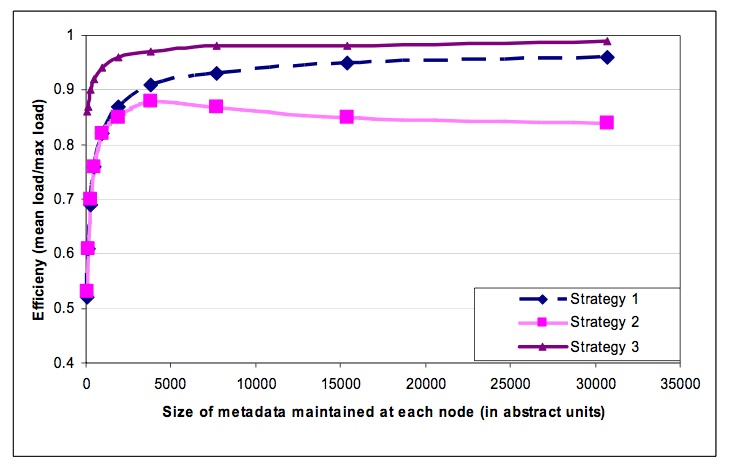
图 8:30 个节点、N=3 且每个节点元数据量相同的系统,在不同策略下的负载分配效率比较。系统大小和副本数量的值是按照我们部署的大多数服务的典型配置。
6.3 分歧版本:什么时候?有多少?
如前所述,Dynamo 被设计为通过牺牲一些一致性以换取可用性。为了准确理解不同故障对一致性的影响,需要详细考虑多个因素:中断时长、故障类型、组件可靠性、工作负载等。详细地展示这些数据超出了本文范围。不过,本节讨论了一个很好的总结指标:应用程序在实际生产环境中出现的分歧版本(divergent versions)的数量。
数据项的分歧版本在以下两种情况下会出现:第一种是当系统面临诸如节点故障、数据中心故障和网络分区等故障场景时。第二种是当系统处理单个数据项的大量并发写入线程,并且最终多个节点同时协调更新操作时。从易用性和效率的角度来看,最好在任何给定的时间都保证分歧版本的数量尽可能少。如果这些版本不能仅提高矢量时钟进行语法协调,则必须将它们交给业务逻辑执行语义协调。语义协调会给服务带来额外的负载,因此应当越少越好。
在下一个实验中,我们采集分析了 24 小时内返回到购物车服务的版本数量。在这段时间内,99.94% 的请求只看到一个版本;0.00057%的请求看到 2 个版本;0.00047% 的请求看到了 3 个版本,0.00009% 的请求看到了 4 个版本。这说明分歧版本出现的概率还是相当小的。
经验表明,分歧版本数量的增加不是因为故障而导致的,而是由于并发写操作数量的增加。并发写数量的增加通常是由繁忙的机器人(自动化客户端程序)触发的,而极少是人为导致的。由于其敏感性,在此就不做详细地讨论了。
6.4 客户端驱动或服务端驱动的协调
正如第 5 节中提到的,Dynamo 有一个请求协调组件,使用状态机来处理传入的请求。客户端请求会通过负载均衡器均匀地分发给环上的节点。任何 Dynamo 节点都可以作为读请求的 coordinator。另一方面,写请求将由 key 当前的优先列表中的节点来协调。有这种限制是因为,这些首选节点有创建一个新的版本戳(version stamp)的额外责任,该新版本戳在因果顺序上已经包含了被写操作更新的版本。注意,如果 Dynamo 的版本控制方案基于物理时间戳,那么任何节点都可以协调写请求。
另一种请求协调的方式是将状态机移到客户端节点。在这个方案中,客户端应用程序使用一个库(library)在本地执行请求协调。客户端定期选取一个随机 Dynamo 节点,并下载它当前的 Dynamo 成员状态视图。使用此信息,客户端可以确定任意 key 对应的优先列表由哪些节点集组成。读取请求可以在客户端节点上进行协调,从而避免了负载均衡器将请求分配给随机 Dynamo 节点时产生的额外网络跳(network hop)开销。如果 Dynamo 使用基于时间戳的版本控制,写操作要么转发给 key 优先列表中的一个节点,要么在本地被协调。
客户端驱动协调方法的一个重要优点是,不再需要一个负载平衡器来均匀分发客户端负载。通过向存储节点近乎均匀分配 key,隐式地保证了公平的负载分布。显然,此方案的效率取决于客户端成员信息的新鲜程度。当前,客户端每 10 秒随机轮询一个 Dynamo 节点,以获取成员更新。选择基于 pull 而不是基于 push 的方法,是因为前者在大量客户端的情况下具有更好的伸缩性,而且相较于在客户端,只需在服务端维护很少的状态信息。然而,在最坏的情况下,客户端可能持有长达 10 秒过期的成员信息。在这种情况下,如果客户端检测到其成员表过期(例如,当一些成员不可达时),它将立即更新其成员信息。
表 2 显示了相较于服务端驱动方法,使用客户端驱动的协调方法在 99.9 百分位点和平均值的延迟性能提升,测量周期为24小时。从表中可以看出,客户端驱动的协调方法使 99.9 百分位点延迟降低了至少30 毫秒,并将平均延迟降低了 3 到 4 毫秒。延迟降低是因为客户端驱动的方式消除了负载均衡器的开销,以及在将请求分配给随机节点时可能产生的额外网络跳。还可以看到,平均延迟远远低于 99.9 百分位点的延迟。这是因为 Dynamo 的存储引擎缓存和写缓冲区(write buffer)具有良好的命中率。此外,由于负载均衡器和网络会给延迟引入额外的抖动性,因此在响应时间方面对 99.9 百分位点的性能提升明显要高于平均值。
| 99.9th percentile read latency (ms) | 99.9th percentile write latency (ms) | Average read latency (ms) | Average write latency (ms) | |
|---|---|---|---|---|
| Server-driven | 68.9 | 68.5 | 3.9 | 4.02 |
| Client-driven | 30.4 | 30.4 | 1.55 | 1.9 |
表 2:客户端驱动和服务器驱动的协调方法的性能。
6.5 平衡后台和前台任务
除了正常的前台 put/get 操作外,每个节点还需要为副本同步和数据移交(由于提示或添加/删除节点)执行不同类型的后台任务。在早期的生产环境中,这些后台任务引发了资源争用问题,影响了常规 put 和 get 操作的性能。因此,必须确保后台任务只在常规关键操作不受显著影响的情况下运行。为此,后台任务都整合了一种许可控制机制(admission control mechanism)。每个后台任务都使用这个控制器来申请资源(例如数据库)的运行时时间片(runtime slices),这些资源在所有后台任务之间共享。使用基于前台任务监控性能的反馈机制,来改变后台任务可用的时间片数量。
在执行“前台” put/get 操作时,许可控制器会持续地监控资源访问的状况。监控指标包括磁盘操作延迟、锁竞争和事务超时导致的数据库访问失败,以及请求队列的等待时间。这些信息用于判断在给定的时间窗口之内的延迟(或故障)百分比是否接近所期望的阈值。例如,后台控制器检查数据库第 99 百分位数据库读取延迟(在过去 60 秒内)与预设的阈值(比如 50ms)的接近程度。控制器使用这种比较来为前台操作评估资源可用性。随后,它决定有多少时间片可用于后台任务,从而使用反馈回路(feedback loop)来限制后台任务的干扰(intrusiveness )。注意,在 [4] 中也研究过类似的后台任务管理问题。
6.6 讨论
本节总结了在 Dynamo 实施和维护过程中取得的一些经验。许多 Amazon 的内部服务在过去的两年都使用了 Dynamo,它为其应用程序提供了相当高的可用性。特别是,应用程序的 99.9995% 的请求都收到成功的响应(无超时),并且到目前为止还没有发生数据丢失事件。
此外,Dynamo的主要优点是,它提供了必要的配置开关,可以根据根据自己的需求使用 (N,R,W) 三个参数对应用实例进行调优。与流行的商业数据存储不同,Dynamo 向开发人员公开了数据一致性和协调逻辑问题。一开始,有人可能会觉得这样会使应用逻辑变得更加复杂。然而,从历史上看,Amazon 平台就是为高可用设计的,许多应用程序被设计为能够处理可能出现的各种故障模式和不一致性问题。因此,移植这些应用程序到使用 Dynamo 是一项相对简单的任务。对于希望使用 Dynamo 的新应用程序,在开发初期需要进行一些分析,以选择满足业务需求的合适的冲突解决机制。最后,Dynamo采用完整成员关系模型(full membership model),其中每个节点都知道其对等节点承载的数据。为此,每个节点要主动将完整路由表传播(gossip)给系统内的其他节点。对于包含数百个节点的系统,该模型可以很好地工作。但是,将这样的设计扩展到运行成千上万个节点并不简单,因为维护路由表的开销会随着系统的大小的增加而增加。可以通过在 Dynamo 中引入层次扩展(hierarchical extensions)来克服这种限制。 O(1) 复杂度的的动态哈希树(DHT)系统(例如 [14])解决的就是这种问题。
7. 结束语
本文介绍了 Dynamo,一个具有高度可用性和可扩展性的数据存储系统,在 Amazon 电商平台被用于存储许多核心服务的状态数据。Dynamo 提供了所需的可用性和性能级别,并成功地处理了服务器故障、数据中心故障和网络分区。Dynamo 可以增量扩展,允许服务所有者根据当前请求负载进行动态伸缩。Dynamo 允许服务所有者通过调优 N、R 和 W 参数来定制存储系统,以满足他们所期望的性能、持久性和一致性 SLA。
过去一年 Dynamo 的生产使用表明,去中心化技术可以结合起来提供一个单一的高可用性系统。它在最具挑战性的应用环境之一中的成功表明,最终一致性的存储系统可以成为高可用性应用程序的一块基石。
致谢
The authors would like to thank Pat Helland for his contribution to the initial design of Dynamo. We would also like to thank Marvin Theimer and Robert van Renesse for their comments. Finally, we would like to thank our shepherd, Jeff Mogul, for his detailed comments and inputs while preparing the camera ready version that vastly improved the quality of the paper.
参考文献
- Adya, et al. Farsite: federated, available, and reliable storage for an incompletely trusted environment. SIGOPS 2002
- Bernstein, P.A., et al. An algorithm for concurrency control and recovery in replicated distributed databases. ACM Trans. on Database Systems, 1984
- Chang, et al. Bigtable: a distributed storage system for structured data. In Proceedings of the 7th Conference on USENIX Symposium on Operating Systems Design and Implementation, 2006
- Douceur, et al. Process-based regulation of low-importance processes. SIGOPS 2000
- Fox, et al. Cluster-based scalable network services. SOSP, 1997
- Ghemawat, et al. The Google file system. SOSP, 2003
- Gray, et al. The dangers of replication and a solution. SIGMOD 1996
- Gupta, et al. On scalable and efficient distributed failure detectors. In Proceedings of the Twentieth Annual ACM Symposium on Principles of Distributed Computing. 2001
- Kubiatowicz, et al. OceanStore: an architecture for global-scale persistent storage. SIGARCH Comput. Archit. News, 2000
- Karger, et al. Consistent hashing and random trees: distributed caching protocols for relieving hot spots on the World Wide Web. STOC 1997
- Lindsay, et al. “Notes on Distributed Databases”, Research Report RJ2571(33471), IBM Research, 1979
- Lamport, L. Time, clocks, and the ordering of events in a distributed system. ACM Communications, 1978
- Merkle, R. A digital signature based on a conventional encryption function. Proceedings of CRYPTO, 1988
- Ramasubramanian, et al. Beehive: O(1)lookup performance for power-law query distributions in peer-topeer overlays. In Proceedings of the 1st Conference on Symposium on Networked Systems Design and Implementation, , 2004
- Reiher, et al. Resolving file conflicts in the Ficus file system. In Proceedings of the USENIX Summer 1994 Technical Conference, 1994
- Rowstron, et al. Pastry: Scalable, decentralized object location and routing for large-scale peerto- peer systems. Proceedings of Middleware, 2001.
- Rowstron, et al. Storage management and caching in PAST, a large-scale, persistent peer-to-peer storage utility. Proceedings of Symposium on Operating Systems Principles, 2001
- Saito, et al. FAB: building distributed enterprise disk arrays from commodity components. SIGOPS 2004
- Satyanarayanan, et al. Coda: A Resilient Distributed File System. IEEE Workshop on Workstation Operating Systems, 1987.
- Stoica, et al. Chord: A scalable peer-to-peer lookup service for internet applications. SIGCOMM 2001
- Terry, et al. Managing update conflicts in Bayou, a weakly connected replicated storage system. SOSP 1995
- Thomas. A majority consensus approach to concurrency control for multiple copy databases. ACM Transactions on Database Systems, 1979.
- Weatherspoon, et al. Antiquity: exploiting a secure log for wide-area distributed storage. SIGOPS 2007
- Welsh, et al. SEDA: an architecture for well-conditioned, scalable internet services. SOSP 2001